
A decade ago, the term “Data Annotation” for Machine Learning was not so familiar, it has emerged in recent years drastically and the roles of Data Annotation, namely data annotator, labeller or validator have become more recognized. The functions of Data Annotation rapidly evolved since Artificial Intelligence (AI) has gained commercial value and became indispensable for solving major problems, especially that AI applications and Machine Learning (ML) algorithms require labelled data to recognize patterns in what is being fed.
Data Annotation is the process of generating, collecting, organizing, pre-processing, labelling and validating datasets which are the main input for machine learning models.
A ML model learns from annotated datasets and eventually predicts outcomes through patterns, which make it generalize to unforeseen data. The data that is used to train models is called training data. The ground rule for training data is: the cleaner, better pre-processed, error-free and of high quality the dataset is, the more accurate the model’s performance will be.
The rules that are set for Data Annotation when it is targeted to Natural Language Processing (NLP) are relatively strict and entail great language inputs. NLP is one of the primary fields of ML which focuses on processing and understanding human language and the meanings implied within words. ML models, which are implemented by data scientists, aim to fully comprehend human needs and put them into action.
It is worth mentioning that Data Annotation is not always required for machine learning models; in some cases, the models are developed without requiring any annotated datasets but a round of validation or some data engineering tasks are carried out to solve issues with the available data. However, in this article, Data Annotation for the Arabic NLP (ANLP) in specific is the main focus.
Having been managing and liaising Data Annotation projects and pipelines between a group of skillful data scientists and a team of cross-functional annotators all focusing on the same goal: to develop intricate models in one of the most challenging languages, I settled on the urge of writing up this article to discuss some of the difficulties and impediments faced by annotators and data scientists working on Arabic NLP models. These are listed under 2 main aspects; technical and organizational/social ones, in addition to presenting few qualifications that annotators should possess, all summed up in the following points:
Technical Aspects:
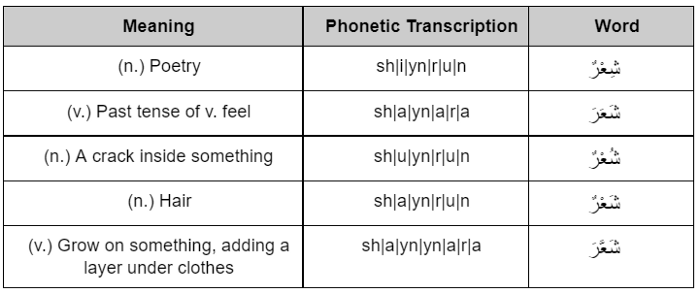
1- Arabic language is one complex language syntactically and semantically. It has a huge variety of vocabulary that exceeds 10 million words, dense grammatical structures and rules, an infinite number of words derived from a 3-letter root (table 1) and many other factors. Additionally, Arabic language is divided into different types which are: Classical Arabic — the language of Quran, ancient Arabic literature, prose and poetry with the most intricate words of the language.
The second type is the Modern Standard Arabic (MSA) that is mainly used in professional settings like media outlets, news segments and official speeches.
The third type is Arabic dialects that are spoken in everyday life. This type is what increases the complexity. The Arab World comprises 22 countries, in which people speak completely different dialects and accents even within the same country, meaning each city, province, or village may have its own accent. That said, someone from North Africa might not understand the accent of an individual from the Levant or the Arabian Gulf and vice versa.
For annotators working on datasets that are predominantly routed in ANLP, this requires a thorough knowledge and proficiency in all Arabic language types which is considered the first challenge. Additionally, It is sometimes required to learn many dialects to be able to read, understand, and sometimes translate dialects to MSA to come up with reliable datasets for models that serve as many people from different countries and origins. Some of which are Dialect Detection, Machine (dialect) Translation, Emotion Detection, Sentiment Analysis, ASR (Automatic Speech Recognition), among others.

2- ANLP is an interdisciplinary and challenging field that requires deep understanding in two complex fields: Deep Learning and Arabic Language. Although I have been working with a group of immensely bright data scientists, researchers and engineers that are highly knowledgeable and have a solid grasp of the Arabic language and its linguistic features, yet NLP requires a huge deal of linguistics and language understanding. Moreover, ML research in Arabic and its applications are still limited if not rare compared to other languages like English, Chinese, French or Korean that are way ahead.
The combined expertise of NLP and Arabic Language is still not so common which normally increases the hindrances that data scientists face with ANLP and indicates that more efforts have to be made in order to guarantee positive outcomes.
Scientists and annotators usually strive to find the needed resources, dig deep in previous studies and navigate through ambiguities and new unproven approaches to the best of their combined knowledge. In some cases, this leads to suboptimal results that require re-doing the whole work which wastes a lot of time and effort.
3- Shortage of Arabic computational linguists: A computational linguist with a solid background works on applying computer science into the language. Due to the novelty of this role and the lack of resources in this field, data annotators sometimes fill the gaps by learning new competencies that are more focused on language models, error analysis, lexicons, spell checking, phonesets or part-of-speech (POS).
Moreover, preparing Arabic datasets for some NLP models demands a major dataset preprocessing step; that is vocalization or “Tashkeel”. Arabic as an objectified concept doesn’t work without vocalization that is used for syntactic, semantic and grammatical applications which is also crucial for the excessive homograph presence in Arabic language. Vocalization changes the meaning of words, their position and tense (table 1). Annotators sometimes are trained to work on such tasks when needed, which require strong knowledge, high concentration levels and a huge responsibility.
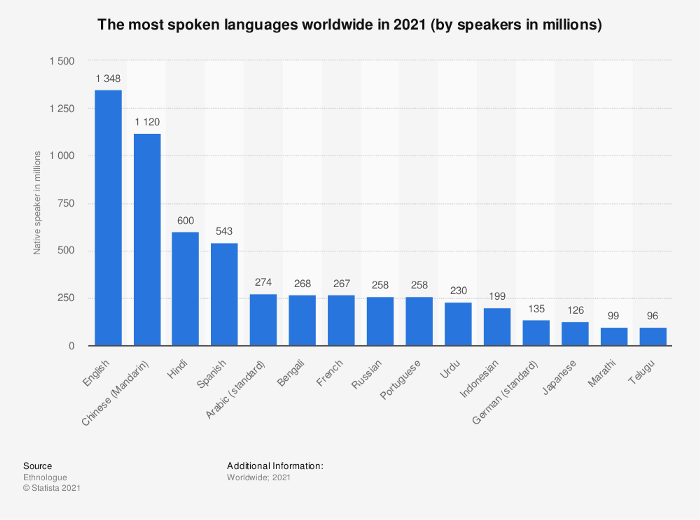
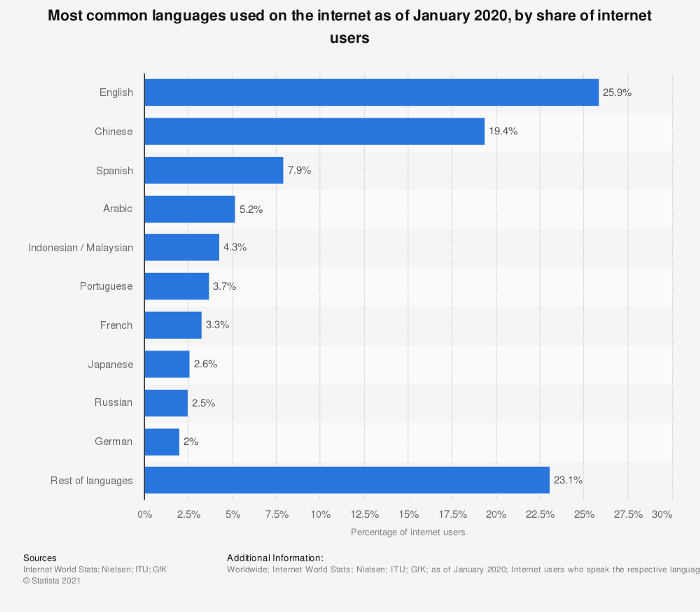
4- Unavailability of rich and consistent Arabic data sources: Arabic digital content is generally known to be scarce. Although Arabic is the fifth most spoken language worldwide and Arabic internet users make up about 65% of the whole population of the Middle East and North Africa, it is still under-resourced. Despite the fact that some sources do exist, the content’s norm is known to be inaccurate and unlikely credible. That being said, shortage of Arabic datasets to be employed is inevitable which adds more complexity. Machine learning models normally rely on the size of the training data that includes a large number of parameters. Small-sized datasets are less prone to produce robust models.
As a result, it is frequently needed to perform extra tasks that might include generating data from scratch, translating datasets that are originally available in English, curating, augmenting and paraphrasing different data sources.
5- Conventions and guidelines: Dealing with Arabic language and NLP has countlesscomplications and details that should not be missed. Wrong “tashkeel”, incorrect usage of a certain Arabic letter/word, tagging and labelling inconsistency, or dealing with numbers and foreign words and their transliteration incorrectly would result in an invalid and erroneous dataset that will have a detrimental impact on the model’s performance.
Due to the wide range of cases that the annotator could face, there must be clear specifications. Consequently, having a full, comprehensive, and well documented data specifications for models’ datasets prior to starting the actual work is a must.
Inclusive conventions are beneficial in having adequate datasets and save time and efforts.
The main issue with the documentation is basically with whose responsibility it is to set the rules; is it the data scientist who requests the dataset based on the model or the data annotator who is fully aware of the language/dialects specifications and model’s predicted outcome?
In practice, the answer is both in most cases. Data scientists and experienced annotators are both required to write the guidelines jointly, each from their perspective until one full clear documentation is produced.
Organizational & Social Aspects:
1- Data Annotation is believed not to build a career path: A big myth!
Data Annotation for ANLP is not yet considered as a solid job that builds strong and skillful individuals with wide expertise. There is a major lack of awareness of this role’s significance among professionals and organizations in our region, most of which are convinced that it is an insecure job and that annotators can be easily replaced for the fair skills they must have to handle this job, not seeing its real value and how emerging it is. Thus, not much focus is being put on this field.
Consequently, employees lose interest in such roles which are underrated, low-paid and do not guarantee professional growth nor secure them with promising and clearly shaped career paths.
As much as this is widely acknowledged, whoever works in data annotation should be aware of how integral this role is for Machine Learning. In fact, this role has a substantial potential for horizontal and technical growth.
2- Handling bad and inappropriate language: a highly used data source for NLP models is social media platforms in which users reflect their interests and personal preferences. Crawling data from these platforms is primary for building NLP models especially for ANLP due to the free style writing and dialectal usage in social media. However, one of the major unpleasant encounters while working in Arabic Data Annotation is coming across this type of data which usually represents users ideology, alliance to certain parties over others, anger, rage, or hatred including offensive language or profanity.
Although this type of data might be extremely useful for models like Profanity Detection, Irony Detection, Emotion Detection and many others, the problem here occurs with the inappropriate language that has to be dealt with, namely sexual, racial, blasphemy, swearing among many others especially when the data needs to be cleaned and filtered for other models that shall not contain such content.
Annotators have to go through profanity data in different dialects which makes them bear a burden of such a distressing task, due to the repulsive content that is generally perceived as taboo.
In the end, Data Annotation is a booming field that is projected to worth more than $5 Billion by 2028. Many businesses are adopting data driven approaches due to its huge and significant value. ANLP in specific is now the core technology for many growing companies that are customer focused and client centric.
Many other obstacles are not discussed in this article, but having tackled some of the technical and organizational/social challenges encountered in Arabic NLP Data Annotation, a number of feasible and viable solutions can be employed to solve most of these, which are planned to be covered in subsequent articles.
About the Author
Riham Badawi is a Project Manager at Knowledge AI Inc, and an expert in Data Annotation for Arabic NLP with expertise spanning for more than 10 years. A graduate from University of Jordan, she is an advocate and proponent of women’s empowerment and strives to excel in her field to set a professional standard. Badawi has previously managed many projects for different sectors including Telecommunication, E-learning, Education, AI and Machine Learning.